
how I use chatgpt
first impressions on a new tool

this post is a bit more off the cuff than usual. rather than expositing beautifully as is my custom (or so I'd like to imagine), I wanted to infodump about how I use chatgpt. I'm not yet ready to call it "indispensable," but if it went away tomorrow, I would be extremely sad
when I was a kid, after spending enough time online, I developed a reflex to search for answers to whatever idle questions I had, instead of asking an adult or just wondering about it without resolution. more recently, I noticed I've developed a new reflex: when I'm confused about something I'm reading, or want more information or perspective, or want to explain in my own words with feedback to solidify my understanding, I talk to chatgpt
but the way most people talk about gpt is very different from my experience. agi diehards see it as a stepping stone to god, startup threadbois see it as a gadget to chase low-effort cash, and normies see it as fugazi. I just see it as a new kind of lever
I first tried gpt when chatgpt came out in december and found myself deeply unimpressed. it was amusing to fool it into producing verboten content, it was interesting how natural its use of language was, but I thought it was a toy. sometimes I would ask it questions of fact, but more often than not, it was confidently wrong. I tried to collaborate with it on advent of code, working in racket, and it was worse than useless. it unerringly delivered broken code, then obsequiously responded to any complaint with even more broken code. I forgot about it for a while after that
in march, I was working on my article "one with the machine," about the first dreams of cyborgism and human intelligence augmentation by vannevar bush and jcr licklider. gpt4 was out and I still hadn't tried it, hesitant to pay the subscription fee after feeling disappointed by 3.5. I met a friend in a restaurant in bangkok and told her about what I'd been writing and my hopes for human-in-the-loop systems, and she tried to sell me on gpt. I complained about 3.5 while she assured me 4 was better. I left still unconvinced, but starting to doubt
it clicked for me when I remembered richard hamming. hamming writes in the art and science of engineering about the programmers of his past, confident wizards of assembly, who refused out of stubborn pride to adopt the compiler. they could do the work better themselves, they asserted. and they were right. in the days before modern optimizing compilers, it was easy for a capable programmer to produce assembly of substantially better quality than whatever the machine would generate
but they were foolish. the point of the compiler wasn't to create better assembly. it was to free the programmer's cognitive resources, offload more work to the machine, let them build faster, or let them build grander
esr makes the same point in his seminal "hacker howto":
And, actually, the more you can avoid programming in C the more productive you will be. C is very efficient, and very sparing of your machine's resources. Unfortunately, C gets that efficiency by requiring you to do a lot of low-level management of resources (like memory) by hand. All that low-level code is complex and bug-prone, and will soak up huge amounts of your time on debugging. With today's machines as powerful as they are, this is usually a bad tradeoff—it's smarter to use a language that uses the machine's time less efficiently, but your time much more efficiently. Thus, Python.
I realized, after reflecting on the conversation with my friend, that I was making the same mistake as the assembly programmers. I had been using chatgpt wanting to find a reason to dismiss it. if gpt was a mere toy, then I wouldn't have to change anything about how I work. I could keep going on reading books and writing code and doing all the things I was used to without having to change a thing. but if gpt was the real deal, I would have to adapt
I've always prided myself greatly on my ability and eagerness to adapt to anything, and this was the first time in my life I caught myself behaving like an old person. so it was this feeling of shame, rather than any new insight into the value of the tool, that got me to try again
the first time I tried gpt, I demanded it bend to me, accommodate the way I wanted to work and the way I tackled problems. and when it failed, I wrote it off
this time, I wanted to do the opposite: bend to the tool, understand how it wants to work, try my best to dance with it, and then evaluate whether it would be of use to me. this is not to ascribe agency to it. a similar dance was required for the spinning jenny and the threshing machine: a new way of working, a collaboration, even with dead matter
also I paid sam altman $20. it turns out gpt4 is a lot fucking better than 3.5
here is what I have learned of the dance. the more I use gpt, the less problems I find I have with it. a few simple rules come to mind which will improve your experience if you struggle to make it useful
the "stochastic parrot" crowd would have you believe gpt is useless because it can’t help but output nonsense, because it can’t reason, because it’s uncreative. but thinking and creating are not gpt’s job. that’s your job. gpt is a helpful assistant that can automate drudgery, spot-check your output, sift through and condense the information you give it
as licklider said in 1960:
In the anticipated symbiotic partnership, men will set the goals, formulate the hypotheses, determine the criteria, and perform the evaluations. Computing machines will do the routinizable work that must be done to prepare the way for insights and decisions in technical and scientific thinking. Preliminary analyses indicate that the symbiotic partnership will perform intellectual operations much more effectively than man alone can perform them.
The hope is that in not too many years, human brains and computing machines will be coupled together very tightly, and that the resulting partnership will think as no human brain has ever thought and process data in a way not approached by the information-handling machines we know today.
I’m sure there are many other ways to use gpt, but this is the approach I take, and I have found it to be very fruitful. and I feel I’ve only scratched the surface
note that I know very little about the dev side of ai beyond feedforward with backprop, this is entirely my perspective as an end-user
use gpt4
it's just better in every way. I would only ever use 3.5 now if I was doing something trivial in bulk over the api and wanted to save money
gpt is a wordcel
this is the most important heuristic to remember because it runs so counter to all our expectations as programmers of what computers are good or bad at. gpt is a large language model: the closer your task is to a language task, the better it will do
I found it to be hopeless at anything mathematical or strictly quantitative. studying undergrad organic chemistry, for instance, it provided excellent and correct summaries and explanations of any topic I could throw at it. but asking it about stoichiometry equations or electron configuations and it was hopelessly out of its depth
it's highly adept at translation. not only are its translations better than google, it can explain nuances of individual words, suggest alternatives, and respond to complaints about its choices. it's also brilliant at routine clerical work like cleaning up messy text or rearranging data into better formats
the one exception to the wordcel heuristic is that it sucks at actually writing. I assume this has more to do with rlhf than limits of the base model itself, but everything it generates is terribly unartful
gpt works best with reference material
if you ask gpt4 a question of fact, its accuracy depends on the content. asking about general topics and broad strokes summaries of people places or things, it does very well. asking about specific niche information can be hit or miss. asking it for real quotes or citations never works
but when you give it a text and ask it about the text, it performs beautifully. it can extract information, summarize, debate, quote. it also seems to make it better at talking about related information not in the text, perhaps by priming it with context
there's a trick people discovered a while back that gpt performs better if you say something like "think step by step." gpt generates tokens based on the previous tokens, and the trick is essentially a special case of the reference material idea: you ask it to generate its own reference material, which means when it goes to generate an answer, that material is in its context window to work off
gpt programs capably in common languages
after using gpt4 to generate python for a bit, I realized my mistake with racket was threefold:
the language was too rare, so there wasn't enough material to generate good output
the language was a scheme dialect, so it often generated subtly wrong racket which may have been valid in other schemes
I was using 3.5
gpt4 python output was magic to me at first. I would describe in natural language what I wanted a program to do, and it would generate something that worked first try. if I needed it to use something not in its training set, I just dumped the code in the window, saying "here's how you do X," and it would use it in the program. if I changed my mind or realized I incorrectly specified the problem, it could easily incorporate corrections
then someone on twitter pointed out that my "natural language" was closer to a precise description in english of the algorithm I wanted it to execute, and I was less dazzled. I also find it struggles more with larger applications and probably can't architect or refactor. but I probably won't ever need to write a one-off script by hand again
gpt works best if you can judge its outputs yourself
this doesn't mean you can't use it to learn new topics. you just need to be a bit critical. be prepared to ask about edge cases or seeming contradictions, ask for clarification, push back on logic or information that feels suspect
I'm always asking questions that start like, "but wait a second, isn't..." and usually it resolves my confusion with something that makes sense and aligns with other things I know. occasionally it gets tripped up or confused itself, and I seek real reference material. I'll usually paste the answer and explain how it got it wrong to get it in context and proceed with what I was doing
treat it like a clever and well-read if overeager undergrad, rather than a distinguished professor, and it becomes a spectacular learning aid
here are some things I've done with chatgpt
cleaning garbled ocr text

my pdf reader has built-in ocr highlight for pdfs without text data. however, the quality of one pdf I was working with was abysmal, producing text hardly better than line noise. instead of improving my ocr workflow, I found gpt could fix it in post
portuguese practice
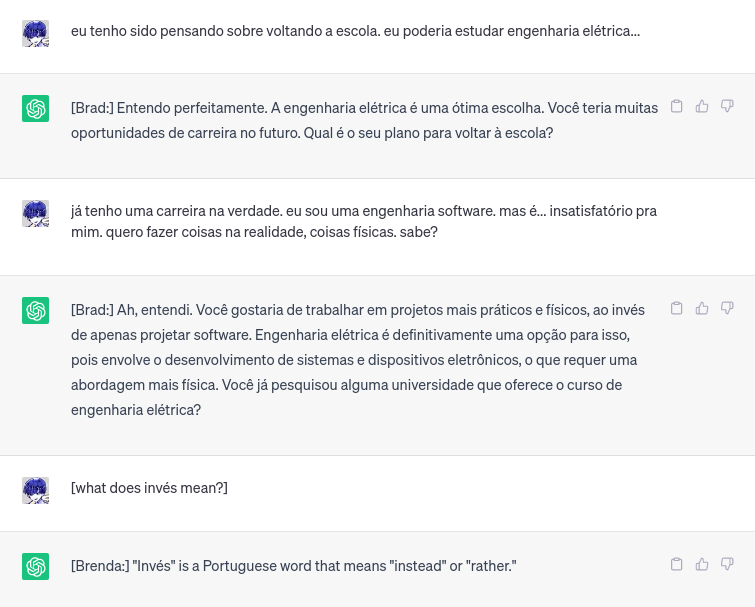
I need to experiment more with the prompt next time I learn a language, and I did this one before gpt4 released, but I've found gpt is a great conversation partner in foreign languages. it can talk about any topic you choose, as long as you want, whenever you want, at any level of simplicity or complexity. its servile enthusiasm is actually kind of nice when you feel self-conscious about your poor language skills
here I told it to play two characters, one that I talk to in portuguese, and another that can answer my questions in english. gpt can get confused when you ask it to do multiple things at the same time, but when you have it label what task it's performing or what character it's playing, it generally can keep them straight
chemistry self-study

I've found gpt4 to be a very capable partner for undergrad chem so far, and it corrects errors for me more often than I need to correct errors for it. whenever possible, I start by pasting text from the book and ask it to explain things in it, rather than asking blind
classical chinese translation

there's a distinction in latin scholarship between "sight-reading," which is straighforward literacy, vs "decoding," a process whereby a non-fluent scholar marks up the definitions and grammatical roles of every word in a sentence, then interprets meaning from that. chatgpt can basically do this automatically, and discuss the results with you, enabling a level of understanding of historical texts somewhere in between reading in the original and relying entirely on a translation
I also found that, because its translations are tin-eared but directionally correct, I could use it to tie professionally translated text to their original sentences. this is of particular interest to me with the xunzi text, which has no facing translation edition, nor any consistent numbering scheme for passages. sometime in the future I might make a facing edition for personal use, using gpt to translate the original chinese line-by-line, then feeding that output back into gpt along with paragraphs from a real academic translation and asking it to substitute in the equivalent sentences
python scripts

I had a project where I took a pdf of the xunzi, dumped the raw text data, used gpt to produce a cleaned copy, vectorized each paragraph, and put them in chroma. then I had a program that would accept a natural language question about the text, vectorize and similarity search it to find the most relevant passages, dump it all in a gpt context and ask gpt to use the texts to answer the question. this was my solution to confabulation: now it could quote and cite
but I also had gpt write the program and all the text cleanup scripts. it performed nearly flawlessly
I don't code much lately so these are just a handful of interesting things I've tried. there's a lot more I'd like to experiment with, especially if I come up with a worthwhile project
I need to try claude. even if it's less capable, the huge context window opens up a wide variety of new usecases. I'd love to run llama locally so I can summarize and analyze private material that I'd never share with openai. but I am a gpuless vagabond and the small quantized model felt basically useless. I still haven't used gpt plugins, custom instructions, browsing, or code interpreter. things move so fast and I barely have the time
I'm too proud to do a gpt wrapper startup, but I do think a lot about workflows for dealing with texts in an automated fashion. smart search, summarization, synthesizing multiple sources, things like that. something like the dream of google books, all the world's knowledge accessible and searchable, but through an intelligent interface
I don't think llms will replace most writers, let alone coders, in the immediate future. the history of ai is riddled with examples of the last mile being the hardest, and it's unclear to me that scaling will endow them with either creativity or agency. but I'm also old enough now to be able to recognize and admit when I don't know what I'm talking about. it's plausible to me that large networks of llms collaborating could be a sea change without a fundamentally new innovation in architectures
gpt4 now, though, is a reasonably capable clerical and research assistant. I think it could at the bare minimum power a renaissance in the humanities, especially once context windows get big enough to contain entire books, as solo scholars learn how to sort through reams of sources in an automated fashion and condense out only what they need. it will probably not get much uptake in traditional academia, but it will be a boon to mad liberal artists
I'm sure more daring users will find all other kinds of uses for it. while I can adapt, I also still feel the tug to make sure I got things right, so I'm less inclined than someone fresh to work to trust its outputs on their face. I'm sure even the forward-looking assembly hackers still peeked at their compiled code and made the tweaks that suited them, just as some people from a different era fiddle with their cars too much and clean their guns too often
failure to change your ways when your ways don't work anymore is death. failure to change when they're simply less efficient is a kind of stasis, but survivable. I know how good my work can be, so I'm not the type of user who can offload even more to the machine, shrug, and say "close enough." I suspect teenagers will have the panache to take llms further than us
most of all, I want the interface to get faster. I want to talk to it as I go about my day. I want to think to it, eventually. I don't think we have the beginnings of god, but we have the beginnings of the next generation of man-machine symbiosis. the distinction between brain augmentation and reference material is nothing more than latency
let's build the exocortex
I have used ChatGPT-4 to generate practice texts in Swahili in increasing difficulty levels as I was learning the language. Swahili is a great language, really easy to learn and pronounce, but there is no so much good learning material out there. It is esp. hard to find explanations for grammatical contructions but ChatGPT-4 had read enough to be able to explain the differences of quite alike words like halafu vs. kwisho or zaidi vs. kuliko. It is really nice that you can ask it about parts of speech and let it explain all parts of a sentence. It is also nice to that the learning text is generates are tuned to my interests and can, e.g., describe cities in the form of a local people's experiences. I also managed to coax it to generate "street Swahili" which is code-switching between Swahili and English as is very common in Kenya and esp. Nairobi.
> I also find it struggles more with larger applications and probably can't architect or refactor.
So far my experience is it’s awesome at refactoring. I’ve pasted in files from a legacy codebase that are ~200 lines, written entirely with outdated web libraries, and asked it to modernize the file / component but keep certain aspects of the logic while fixing some aspect of it.
And it’s been able to do it correctly, to the point where I can just directly paste its result in without changes and everything still works correctly throughout a large enterprise application.
I also only use the Code Interpreter model of GPT-4 for coding tasks, which supposedly has an 8k context window and others report it being more logically consistent.
Also, great post.